

主キーの議論をするとID生成に関する議論になります。今回は、代表的なID生成方法とCloud Spanner等のSaaSデータベースへのマッピングを考えている場合の注意点について、紹介します。
目次
構成
一般的なWebアプリケーションの構成を考えるとフロントサーバ、APIサーバ、DBサーバなどの構成になっています。ユーザ情報をDBサーバに保存する場合は、ユーザを識別するためにユニークなIDをつけると思います。このユーザIDの振り方について考えてみます。
DBサーバが提供する採番機能を利用する
DBには、採番機能があります。postgresqlの場合は、シーケンスオブジェクトというものがあり、シーケンス番号を自動で採番してくれます。例えば、下記の例は、データ追加のタイミングで毎回idが自動で採番されていきます。
CREATE TABLE IF NOT EXISTS test_serial (id SERIAL, name text NOT NULL, CONSTRAINT pk_test_serial PRIMARY KEY(id));この採番機能は、アプリケーション側での実装がいらず一番簡単です。このシーケンスオブジェクトは、一意的、連続的、順序性があるオブジェクトです。下記問題があります。
- 実装時期が比較的新しいため、実装依存である
- パフォーマンス問題をひきおこす可能性がある
シーケンスオブジェクトの問題
一意的、連続性、順序性を担保するためには、
現在の値を取得するタイミングで
- 現在の値を取得するタイミングで、排他ロックを取得する
- 現在の値を取得する
- 次の値をインクリメントする
- 排他ロックを解除する
を行います。この期間に他のユーザがデータ取得を行えないようにする処理(例えば、mutexなど)が実装されます。
連続性からくる問題
連続的に追加されるデータは、物理的に近い領域に格納されます。物理的に近い領域へのアクセスが頻繁に発生していると 特定の物理ブロックへのアクセスが集中して、IO負荷が高くなります。そのため、性能劣化が発生しやすくなります。このような状況を一般的にホットスポットと呼びます。
シーケンスオブジェクト以外に、冗長なカラムを追加してそれをプライマリーキーとすることで、この問題が発生しにくくするということを行うケースがあります。
アプリケーション側で採番する場合
アプリケーション側で採番する場合によく使われる採番方法を紹介します。このようにIDを採番するアプリケーションをID生成器と呼ばれます。ポイントだけ紹介します。
- UUID v1 ・・・タイムスタンプ、クロックシーケンス、ノードから構成される
- UUID v4・・・乱数から生成され、他のversionのUUIDに比べて分散性の高いIDを生成される
- snowflake ・・・twitter社で利用される64ビットのIDが生成される
- ULID・・・128bitからなるID生成器。タイムスタンプと乱数にて構成される
連続性があるIDを利用すると採番が発生する可能性があるので、ある程度の分散性があるものを選択しましょう。
Cloud Spannerベストプラクティスとして
Cloud Spannerのベストプラクティスというドキュメントの中でもホットスポットについて記載されています。Cloud Spannerは、先程紹介したホットスポットの近い物理ブロックが同じサーバだとして読めばよいです。
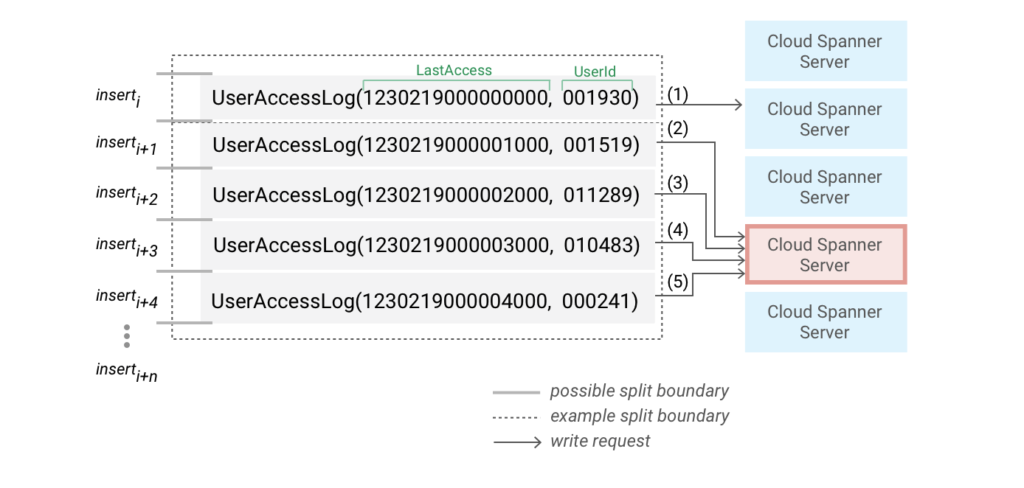
ホットスポットを避けることが推奨されています。連続性が必要ない場合は、一意性だけを保証するID生成器を使ってホットスポットの発生を防ぎましょう。お疲れ様でした。