

最近は、ソフトウェアアーキテクチャの話題などでCleanArchitectureが話題に上がることが多くなってきたと思います。開発する際にも何度か利用して知見が溜まってきたので、その知見を記事にしたいと思います。
目次
CleanArchitectureとは
クリーンアーキテクチャは、Rovert Martin氏(通称 ボブおじさん)がブログ、のちに書籍「Clean Architecture」としてまとめたソフトウェアアーキテクチャです。このブログや書籍では、いくつかのソフトウェアアーキテクチャが記載されています。
- Hexagonal Architecture ・・・ポートとアダプターと呼ばる
- Onion Architecture
- Screaming Architecture
などなど、複数のアーキテクチャが挙げれています。ボブは、これらのアーキテクチャはについて次のように語っています。
細部に多少の違いはあるものの、非常によく似ている。いずれも「関心事の分離」という同じ目的を持っている。そして、ソフトウェアをレイヤーに分割することで、この分離を実現している。また、それぞれ少なくとも、ビジネスルールのレイヤーと、ユーザやシステムとのインターフェスとなるレイヤーを持っている。
書籍 Clean Architecture P199
クリーンアーキテクチャという言葉を知らなくても下記の図を見たことがある方もいると思います。この図は、結構よく出来ていて理解できています。
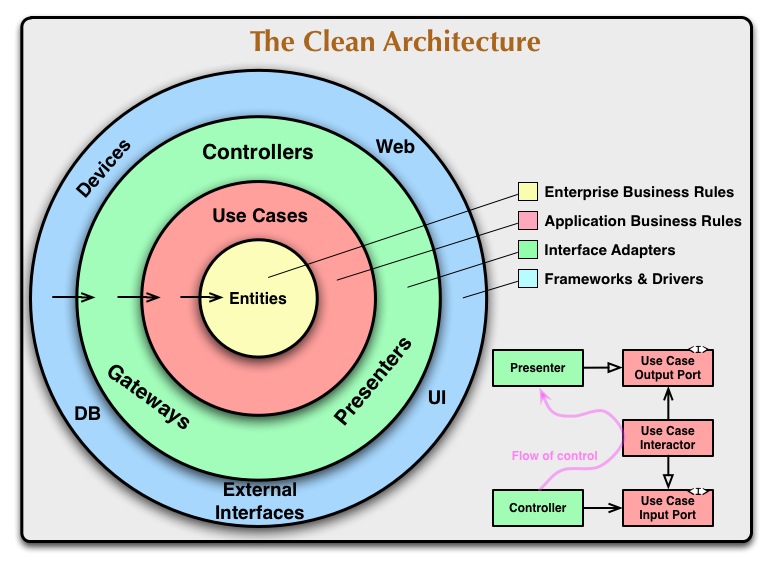
ボブ自身は、このクリーンアーキテクチャについて、次のことを言っています。
- フレームワーク非依存・・・アーキテクチャは、ライブラリに依存しない。
- テスト可能・・・ビジネスルールは、UI、データベース、ウェブサーバ関係なくテストできる。
- UI非依存・・・UIの変更は、ビジネスルールの変更に影響を与えない。
- データベース非依存・・・データベースのルール(SQL,NoSQL, インメモリなど)によらない。
- 外部エージェント非依存・・・外界のインターフェスを知らない
これは、全て上の図でいう青い部分の領域の話です。
実は守るべきルールは2つ
このアーキテクチャで理解しないといけないのは、2つだけだと思っています。
同心円の→が内側に向かっているのが理解できると思います。
- 同心円の→が内側に向かっている・・・依存性のルール
- 制御の流れと依存の流れを逆転する・・・依存関係逆転の原則(DIP)
書籍を読んでみるとわかるのですが、ボブ氏は、この2つのルールの説明をするためにSOLID原則など、いろいろな例を使い原則を紹介しています。詳しくは書籍を読んでもらえればわかると思うのですが、よくアーキテクチャの図などを見ると、全てをそれに適用しようとする人がいるのですが、ボブ自身も円の形も4つになることばかりではないと語っているので、このあたりは柔軟に適用するのが良いと思います。もう少し掘り下げて、見ていきましょう。
依存姓のルールとは
ここであげられている登場人物は、4ついます。このリストでは、下にいくほど上位レイヤーの考え方になります。
- フレームワークとドライバ
- インターフェスアダプター
- アプリーケーションのビジネスルール
- 企業のビジネスルール
フレームワークやドライバ、その他、例えばDBに関しては正直、一番関心が薄いレイヤーになります。インスタンスフェースアダプターは、フレームワークとアプリーケーションロジックの橋渡し、アプリーケーションロージックは、ドメイン駆動開発で言うところのドメインサービス、ユースケースなどの領域、企業のビジネスルールは、ドメイン駆動開発の言葉で説明するとドメインオブジェクトです。
ここで重要なことは、依存の方向が常に上位方向へ向かうことです。ここは守るべきポイントです。例えば、WebAPIなどで、処理の流れベースでコードを記載すると下記のような処理フロートなります。Controllerなどは省いて、必要最小限の図にしてあります。

ECサイトを想定した場合、ユーザの購入履歴を取得するようなユースケースを考慮した場合には、下記のようなことをします。少し無理やりな例かもしれません^^;
- ユーザIDから購入履歴を
DBが取得する - 最近の購入履歴から、おすすめをA社のレコメンドサービスに問い合わせる。
- 取得したDBの内容をユーザに返却できる
上のような実装になる場合、DB、A社のようなキーワードがユースケースにあらわれていることが多くあります。このユースケースを利用者の目線で見直してみると
この実装で困る点は、処理速度等を考慮して、DBがMaria DBなどのSQLを利用している形から、mongoDBのようなNonSQLへ変更したいというようなケースが発生した場合、あUse CaseがDB(=Marid DB)を利用しているので、mongo DBを利用するように接続の仕方、DBへのデータ保存方法などの部分を含めて、変更する必要が出てきます。これは、レイヤー訳の観点ではよくありません。では、どうすれば良いのでしょうか。
このユースケースを利用者の目線で見直してみると
- ユーザ識別子をもとに必要な購入履歴を取得する。
- 購入履歴からレコメンド情報を取得する。
- 取得した情報をユーザに返す
のようにどこから(MariaDB, mongoDB)、どのように(SQL, コレクションといったDBの構造)といった情報が入らない形で表現することができます。これを先程の図に適用してみると、下記のようになります。赤い部分が増えています。※今回の考え方は、フレームワークとユースケースの間についても同じことが言えます。
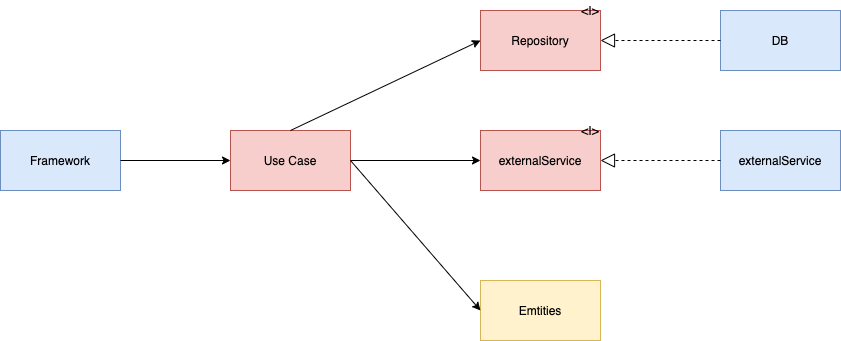
ユースケース目線で考えると必要な情報を取得するなにかがいる想定で考えれるという形です。Use Case->DBという制御フローの流れが、Use Case->Repostioryという形に切り替わっています。このRepository、DBの部分で依存関係が逆転しています。これを依存関係逆転の法則(DIP)と言います。なんかコードが増えてややこしいなぁーって思う人も結構いるようですが、良い面もあります。
悪い面- コードが増える
- ファイルが増える
良い面
- 外部リソースに依存しないようにできる
良い面てそれだけ?と思う方もいるかと思いますが、これはコードやファイルが増えることよりもメリットが高いです。例えば、次のようなケースです
- DBの開発が遅れる(スタドプロシージャの実装、スキーマ設計)が起こり、必要な情報をとって表示することができない
DBの開発が遅れるからアプリーケーション側の開発がストップしてしまうでは、効率の良い開発とは言えないので、何かしらの方法をとるのですが、そのとき、Repositoryを実装したDBに変わる何か、例えばメモリに書く代わりのスタブを利用することで、Use Caseのコードを変更することなく振る舞いを変えることができるのです。これは、かなりメリットが高いです。テストに関してもDBと密接に関係している場合、単体テストでもDBが必要になりセットアップしたり、またDBが立ちあがらない等の本来、単体テストでは見る必要のない問題とも離れることができます。このストレスがなくなるのは、開発者としては非常に嬉しいことです。
すべてを適用しないと駄目なのか
図に示されているよな形ですべてを適用しないと駄目なのか?という疑問を持っているかたも多いと思います。例えば、アプリーケーションルールや企業のルールという隔たりがないようなケースも意外とあるので、もし、そのような場合には、一緒にしてしまうというのもありです。大事なことは、依存の方向は、必ず上位へ向くこと
- 大事なことは、依存の方向は、必ず上位へ向くこと
- 制御の流れで境界をまたがなくてはイケない場合(さきほどの例のDBとRepository)の部分には、DIPするということ
この2点を守ることで、テストしやすくメンテナンスがしやすいアプリケーションが開発できるということ。
おわりに
今回は、Rovert Martin氏が提唱したCleanArchitectureが伝えようとしているポイントを2点絞ってまとめてみました。この2点を守ることで自然に同心円のようなアーキテクチャになったのが正解で、あの絵の通りにしなかればならないという形で、このクリーンアーキテクチャを適用すると苦労するかもしれません。DDDのようなアーキテクチャに比べるとライトな感じがするので、導入のハードルは低いと思いますので、是非導入してみて下さい。